 Isaac's Tech Blog
Isaac's Tech Blog
LLM embedding & vector database의 소개
Mon 30 December 20241. 서론 (Introduction)
1.1 LLM 임베딩(Embeddings)의 정의
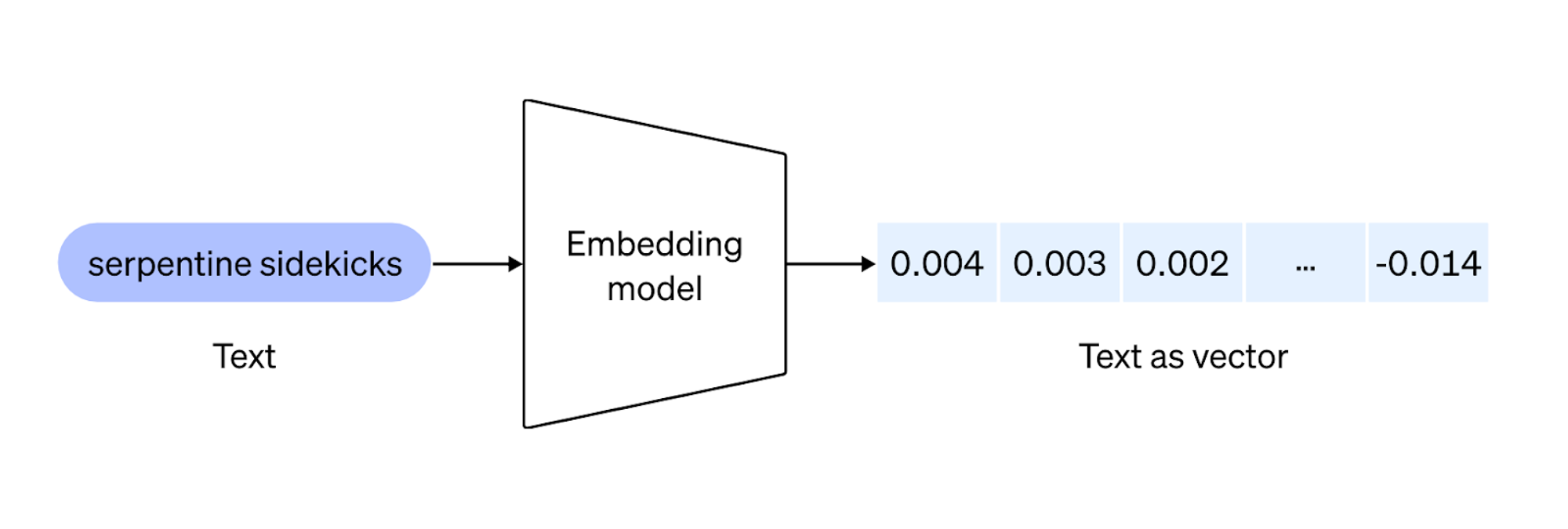
대형 언어 모델(LLM)에서의 임베딩은 단어, 문장, 혹은 문서와 같은 텍스트 단위를 의미·문법 정보를 담은 숫자 벡터로 변환한 것을 말합니다. 텍스트를 연속적인 벡터 공간으로 바꾸어, 서로 다른 텍스트 간의 유사도(관련성)를 정량화할 수 있도록 해줍니다. 이러한 임베딩은 모델 학습 과정에서 습득되어, 미묘한 언어적 특징까지 인코딩합니다. 따라서 유사도 검색이나 분류, 군집화 등의 다양한 작업을 위한 핵심 빌딩 블록 역할을 합니다.
1.2 역사적 배경: Word/LLM 임베딩의 진화
현대 LLM 이전에는 Word2Vec, GloVe 같은 방식으로 정적(Static) 임베딩을 사용해, 각 단어당 하나의 벡터를 할당했습니다. 이후 Transformer 기반 모델(BERT, GPT 등)이 등장하면서 맥락(Context)에 따라 달라지는 임베딩이 가능해졌고, 이는 감성 분석이나 QA 같은 작업 성능을 크게 끌어올렸습니다. 현재는 더 대규모의 모델로 발전하며, 더욱 깊은 의미를 담아낼 수 있는 임베딩을 제공하고 있습니다.
1.3 왜 벡터 임베딩이 특별한가
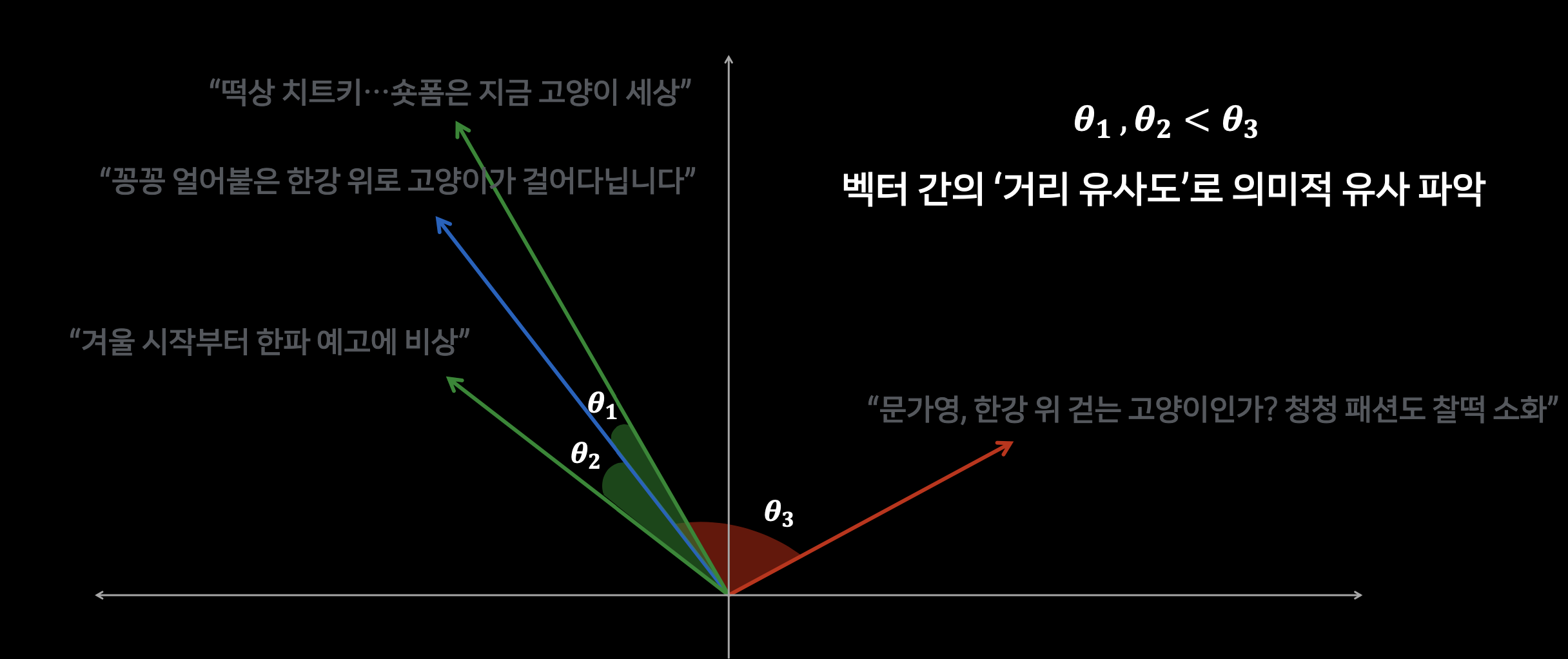
벡터 임베딩은 텍스트의 표면적인 단어 매칭을 넘어 기저 의미(Semantics) 를 포착하기 때문에 각기 다른 단어로 구성된 문장도 의미가 유사하면 근접한 벡터로 표현됩니다. 이는 현대 NLP 기반의 시맨틱 검색, 추천 시스템 등에서 핵심적입니다. 기존의 기호(symbolic) 접근과 달리, 이 밀집(dense) 벡터는 도메인이나 작업을 가리지 않고 범용적으로 활용하기 유리합니다.
< 백터 검색의 정점에 오르다 | DAN24 >
2. LLM에서 임베딩 추출하기 (Retrieving Embeddings from LLMs)
2.1 LLM의 전형적인 아키텍처
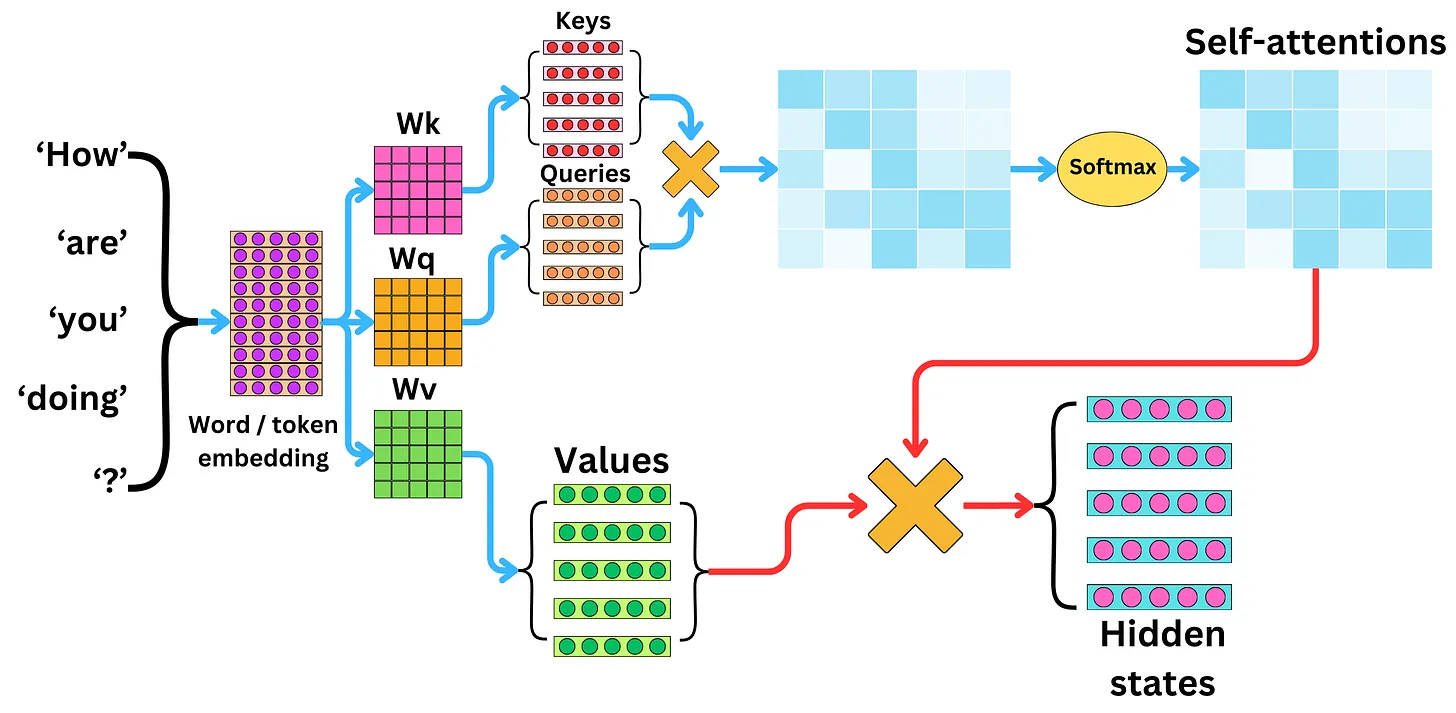
https://newsletter.theaiedge.io/p/understanding-the-self-attention
대부분의 대형 언어 모델은 Transformer 구조를 사용하며, Self-Attention 기법으로 맥락적 관계를 학습합니다. 모델은 여러 층(예: 12층, 24층 이상)으로 구성되어 입력 텍스트의 표현을 점진적으로 정교화합니다. BERT의 [CLS] 같은 특수 토큰이나 마지막 히든 레이어를 임베딩으로 활용하는 경우가 많습니다. 어떤 위치에서 벡터를 추출해야 최적의 임베딩이 나오는지 이해하는 것이 중요합니다.
2.2 레이어 선택과 풀링(Pooling) 전략
임베딩 품질은 어느 레이어에서 추출하느냐에 따라 크게 달라집니다. 최종 히든 레이어를 쓰는 경우도 있지만, 더 범용적 특징을 얻기 위해 중간 레이어를 활용하기도 합니다. [CLS] 토큰을 사용하는지, 모든 토큰 벡터를 평균(average)하거나 맥스 풀링(max pooling)하는지에 따라 결과가 달라집니다. 이러한 선택은 적용 과제와 도메인에 따라 달라집니다.
2.3 임베딩 추출 실무 가이드
개발자는 일반적으로 Hugging Face Transformers와 같은 라이브러리를 통해 사전 학습된 모델을 간단한 코드로 불러와 임베딩을 생성합니다. 전형적인 워크플로는 텍스트를 토크나이즈(tokenize)하고, 모델에 입력한 뒤 특정 레이어의 출력을 추출하는 식입니다. 분야 특화 작업(예: 법률, 의료 등)에서는 파인튜닝이나 도메인 적응이 필요할 수도 있습니다.
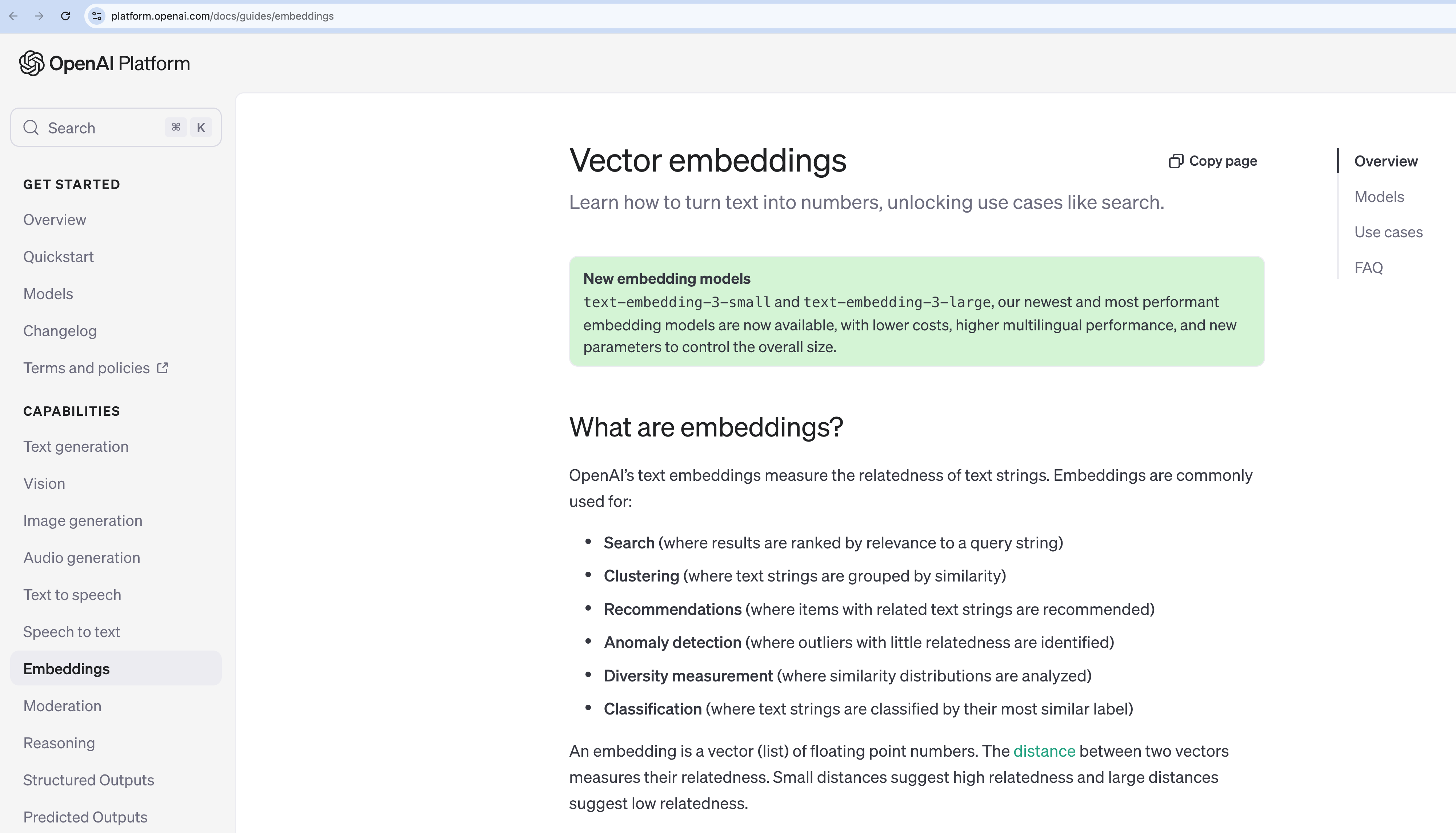
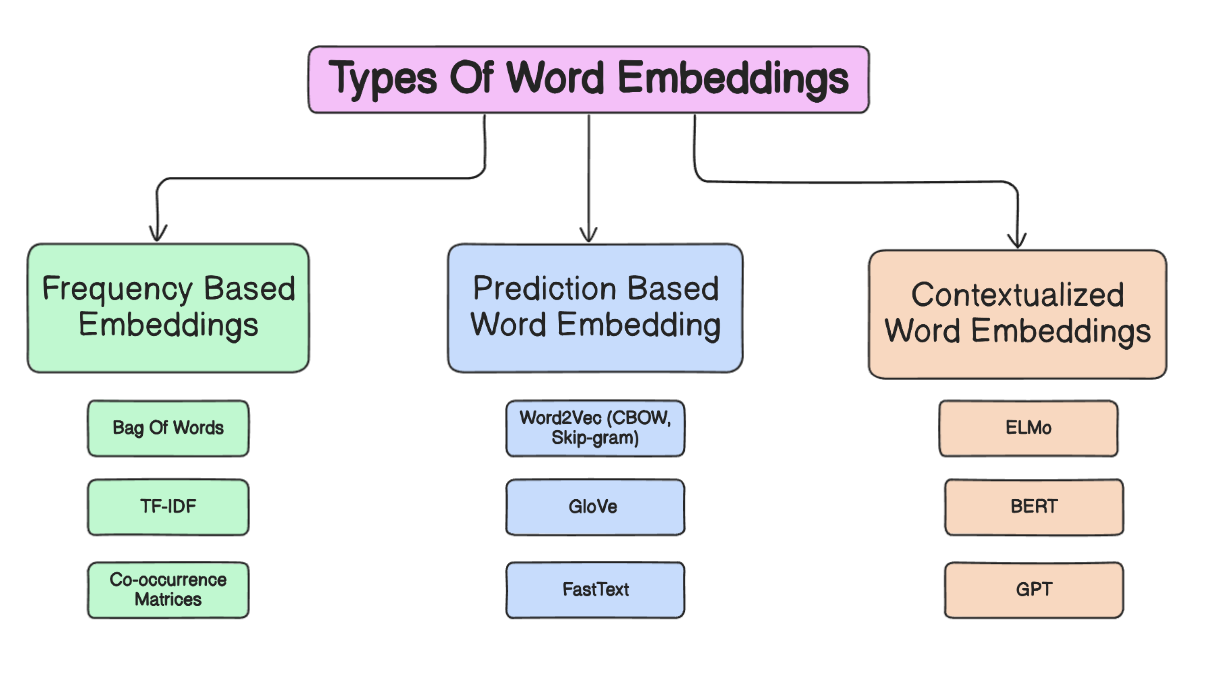
3. 임베딩의 종류 (Types of Embeddings)
3.1 단어 수준 임베딩 (Word-Level Embeddings)
단어 수준 임베딩은 각 단어마다 밀집 벡터를 할당합니다. Word2Vec 같은 정적 임베딩은 맥락에 상관없이 동일 벡터를 사용하지만, Transformer 기반 시스템은 단어가 등장하는 맥락에 따라 벡터가 달라집니다. 품사 태깅, 기초적인 텍스트 유사도 등에는 쓸 만하지만, 더 긴 문맥이나 담화 정보를 반영하기에는 제한적일 수 있습니다.
3.2 문장 수준 임베딩 (Sentence-Level Embeddings)
문장 전체를 단일 벡터로 표현하여, 개별 단어보다 포괄적인 의미를 담아냅니다. Sentence-BERT나 Universal Sentence Encoder 등이 대표적이며, 시맨틱 검색이나 문장 클러스터링 같은 작업에서 자주 사용됩니다. 서로 다른 표현을 쓰더라도 의미가 유사하면 문장 벡터가 가깝게 위치해 정확한 검색 및 분류를 가능하게 합니다.
3.3 문서/단락 수준 임베딩 (Document/Paragraph-Level Embeddings)
단락이나 전체 문서처럼 긴 텍스트를 하나의 벡터로 요약하여 주요 아이디어를 포착합니다. 문서 분류, 요약, 대규모 정보 검색에 유용합니다. 다만 너무 긴 텍스트를 한 벡터에 압축할 경우 정보 손실이 발생할 수 있어, 청크(chunk) 단위 분할이나 계층적(hierarchical) 임베딩 기법을 고려해야 합니다.
3.4 특수 목적 임베딩 (Specialized Embeddings)
의료, 법률, 금융처럼 특수 도메인에서는 전문 용어와 맥락을 더 잘 반영하는 도메인 특화 모델이 필요합니다. 예컨대 CLIP과 같이 텍스트와 이미지를 모두 다루는 멀티모달 임베딩은 다양한 형식의 데이터 간 매핑을 수행합니다. 이처럼 특정 도메인 코퍼라로 파인튜닝을 수행하면 해당 분야 과제에서 성능이 크게 향상됩니다.
4. 벡터 데이터베이스의 역할 (Role of Vector Databases)
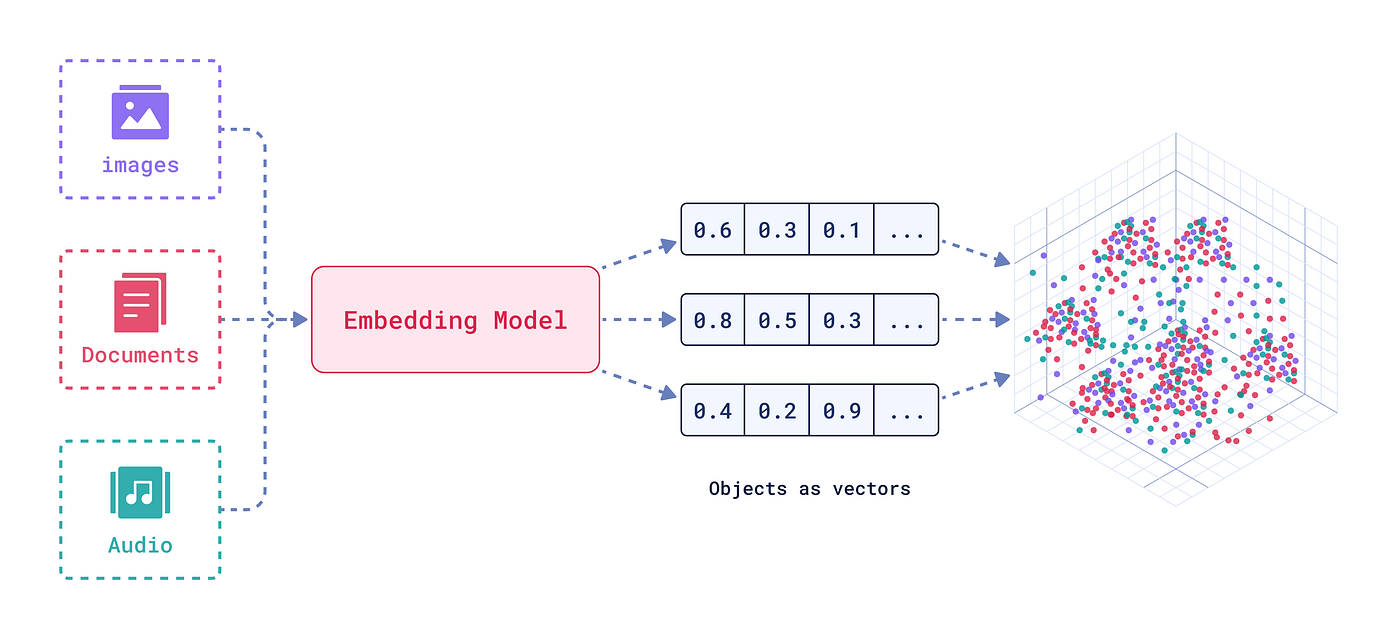
4.1 벡터 데이터베이스란?
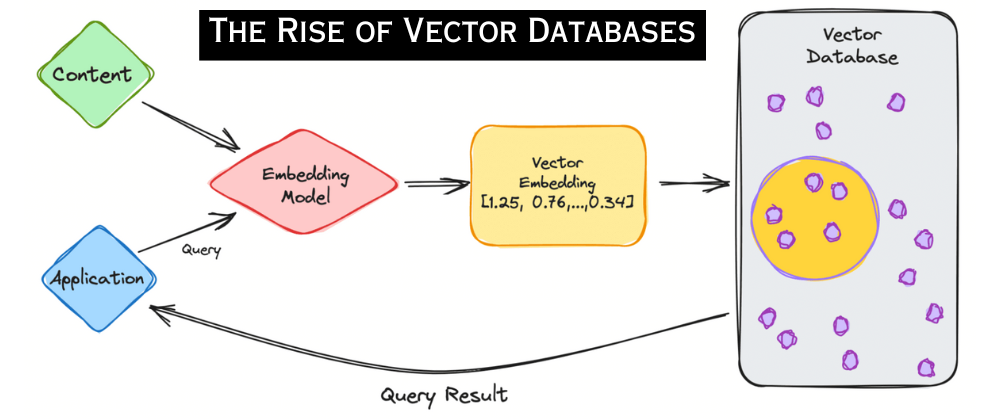
벡터 데이터베이스는 고차원 임베딩 벡터를 대량으로 저장·검색할 수 있도록 특화된 데이터 스토어입니다. 기존 관계형 DB는 대규모 벡터 연산에 한계가 있습니다. 반면 벡터 DB는 유사도 검색, 추천, 이상 탐지 같은 작업을 위해 최근접 이웃(Nearest Neighbor) 알고리즘을 빠르게 수행하도록 설계되었습니다.
4.2 핵심 기능 (Key Features)
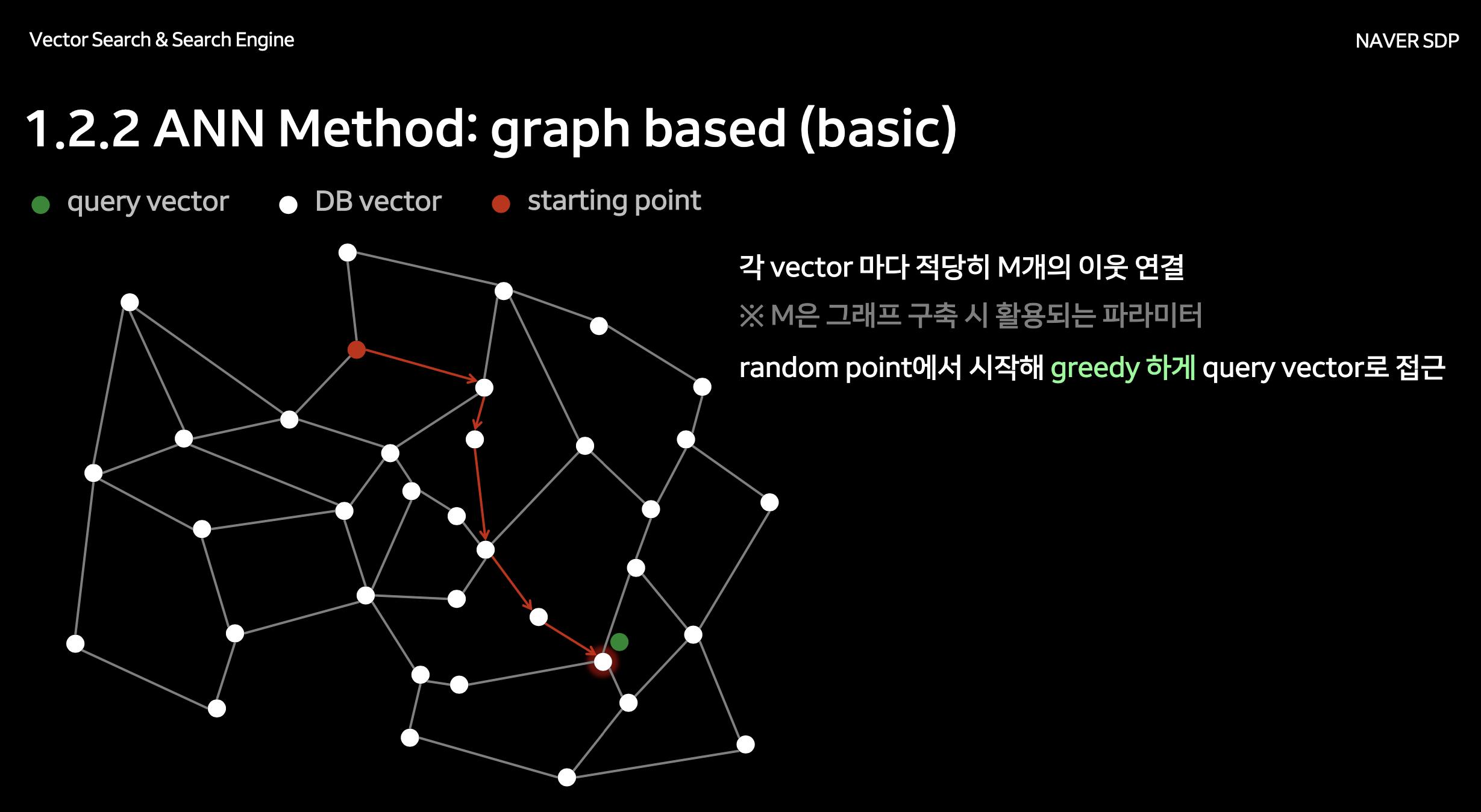
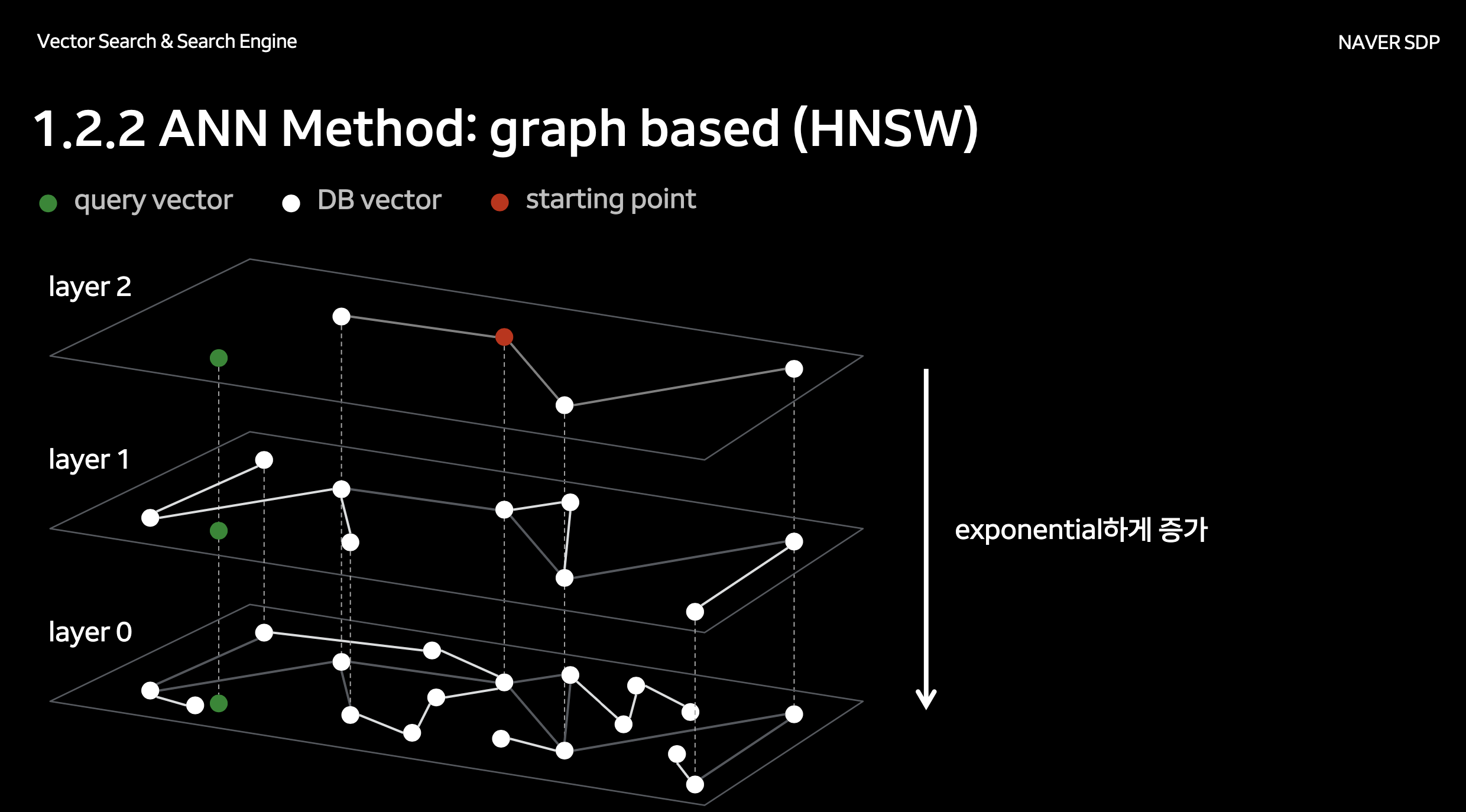
가장 가까운 상위 k개의 벡터를 빠르게 찾는 기능, 근사 최근접 이웃(ANN) 인덱싱, 그리고 HNSW(Hierarchical navigable small world) 같은 특수 데이터 구조가 중요합니다. 대규모 데이터를 처리하기 위해서는 샤딩(sharding), 파티셔닝(partitioning), 분산 인덱싱 같은 확장성이 필수적입니다. 일부 벡터 DB는 메타데이터 필터링이나 기존 데이터 파이프라인과의 연동 기능도 제공합니다.
4.3 대표적인 벡터 데이터베이스와 프레임워크
자주 쓰이는 라이브러리 및 서비스로는 FAISS(Facebook AI Similarity Search), Milvus, Pinecone, Weaviate 등이 있습니다. FAISS는 오픈소스 라이브러리 중 고성능으로 유명하고, Milvus나 Weaviate는 클러스터 관리 및 API 등 종합 기능을 제공합니다. Pinecone 같은 관리형 서비스는 인프라 설정이 간단해 프로토타입을 빠르게 만들기에 적합합니다.
4.4 벡터 데이터베이스 아키텍처(pinecone as example)
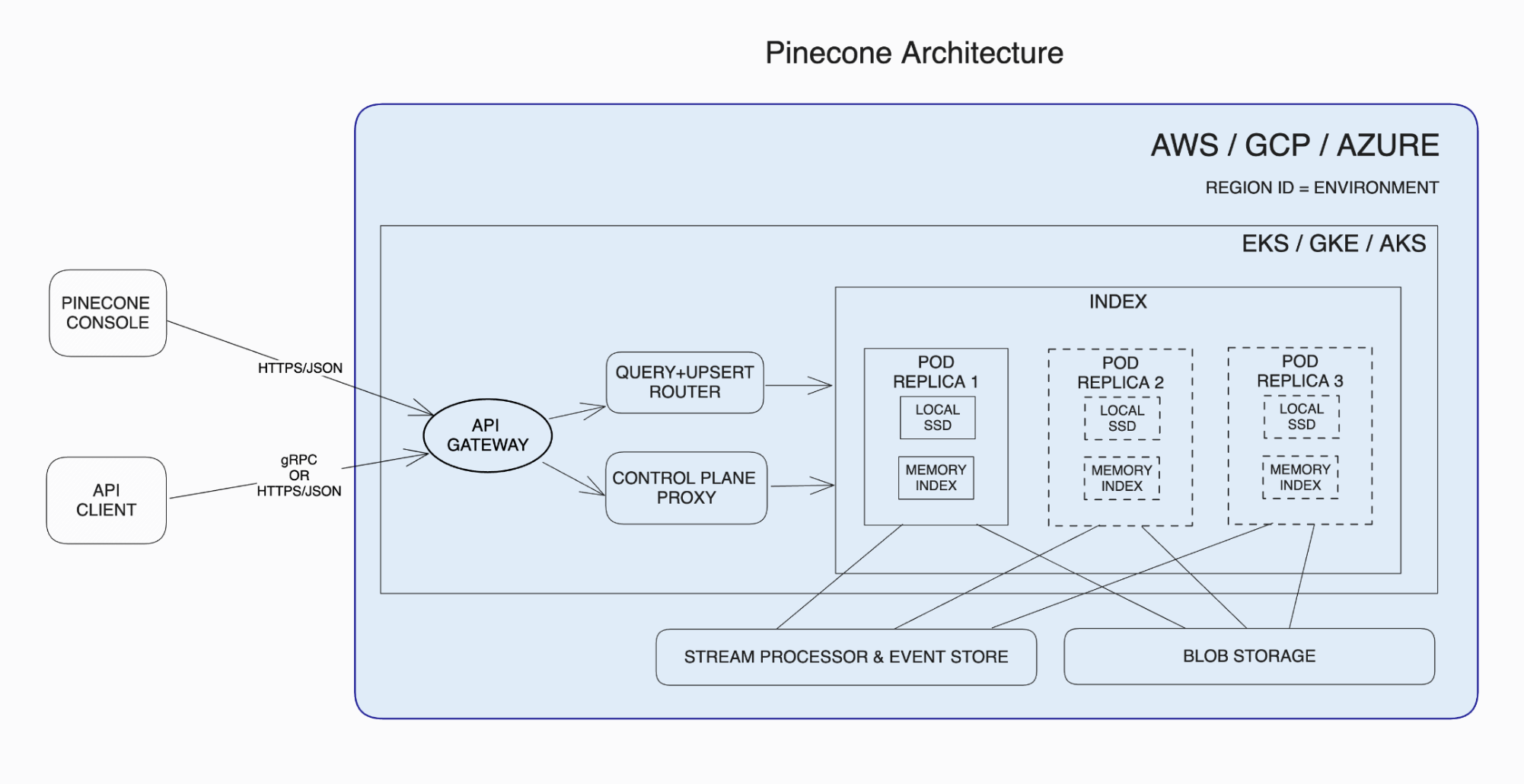
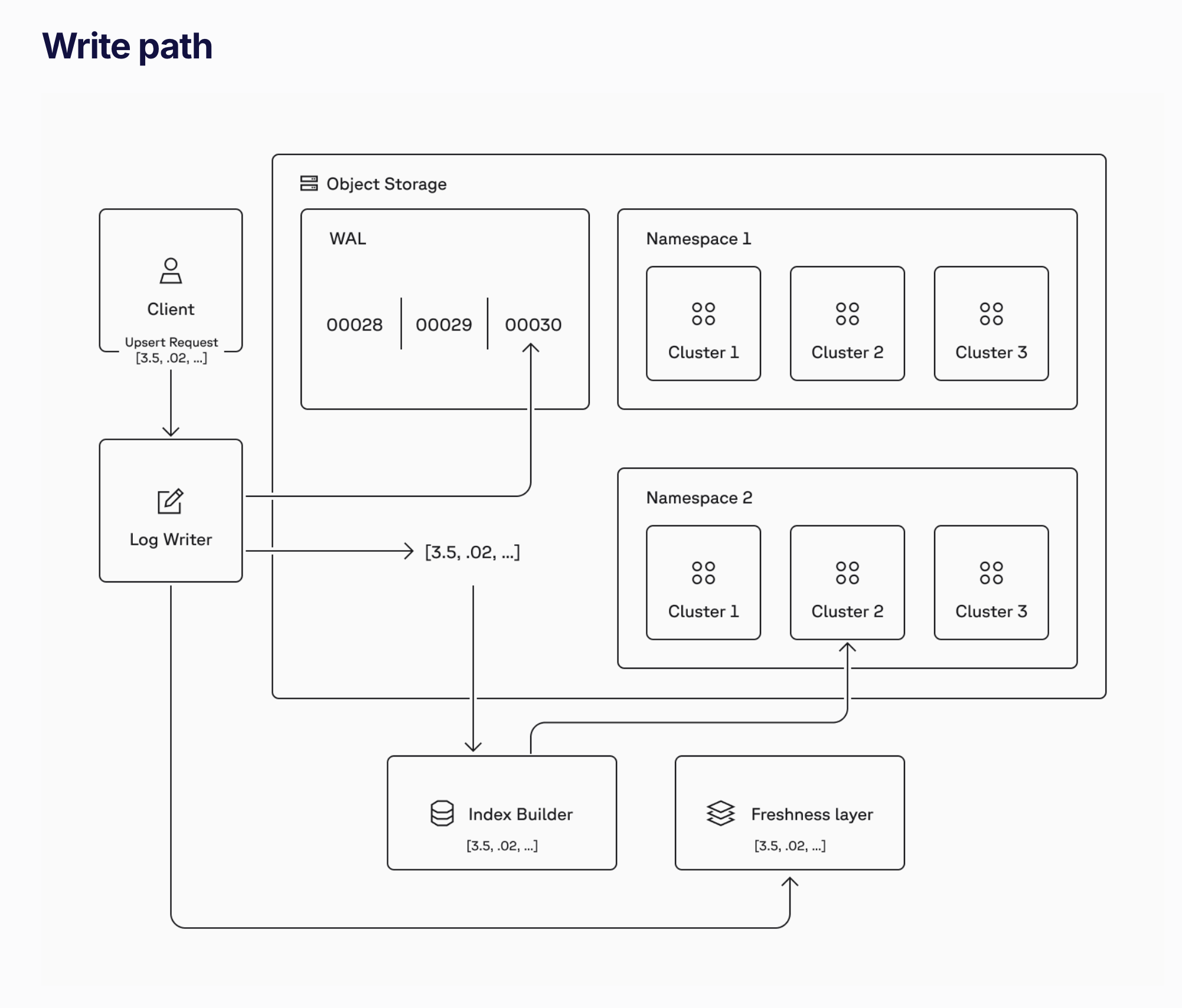
pinecone write path architecture
대부분의 벡터 DB는 고차원 검색에 필요한 연산 복잡도를 줄이기 위해 특수 인덱스 구조를 사용합니다. 대규모 처리를 위해 데이터를 여러 샤드로 나누어 저장하기도 합니다. 일부 시스템은 캐시 계층이나 동적 인덱싱을 통해 실시간 업데이트를 지원합니다. 이러한 아키텍처적 요소를 이해하면 검색 속도와 정확도를 최적화하는 데 도움이 됩니다.
5. 벡터 유사도 측정 기법 (Vector Similarity Measures)
5.1 공통 유사도·거리(metric) 지표
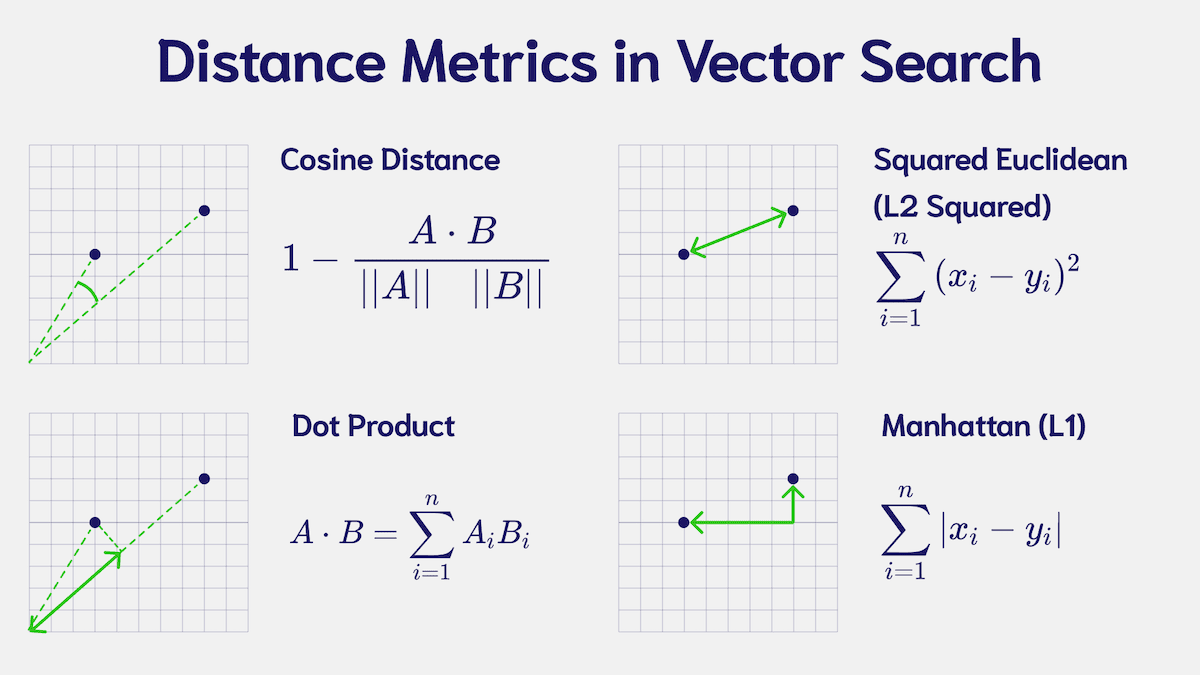
코사인 유사도(Cosine similarity), 도트 프로덕트(dot product), 유클리드 거리(Euclidean distance) 등이 벡터 간 “가까움”을 평가하는 대표 지표입니다. 코사인 유사도는 벡터 크기보다 각도에 초점을 맞춰서, 벡터 스케일 차이에 강인합니다. 도트 프로덕트는 계산이 빠르지만 벡터 크기의 영향을 많이 받습니다. 유클리드 거리는 기하학적으로 직관적이지만, NLP에서는 상대적으로 덜 쓰일 때도 있습니다.
5.2 올바른 지표 선택하기
어떤 유사도 측정을 쓸지는 데이터 특성과 목표 과제의 성능 요구에 달려 있습니다. 코사인 유사도는 텍스트 임베딩에서 방향성을 중시하기 때문에 가장 널리 쓰이며, 도트 프로덕트는 벡터 크기가 의미(예: 가중치)를 갖는 경우 유리할 수 있습니다. 여러 메트릭을 검증 세트에서 비교·평가해 보는 것이 안전한 방법입니다.
5.3 근사 최근접 이웃(ANN) 기법
HNSW(Hierarchical Navigable Small World), IVF(Inverted File Index), Product Quantization(PQ) 등은 수백만~수십억 개에 달하는 벡터를 효율적으로 검색할 수 있게 해줍니다. 정확도와 속도 간 균형을 맞추기 위해, 유사도 계산을 근사하는 접근입니다. HNSW는 낮은 지연 시간에 높은 재현율을 제공하고, PQ는 메모리 사용량을 크게 줄일 수 있는 장점이 있습니다.
6. 활용 사례 (Applications and Use Cases)
6.1 시맨틱 검색 (Semantic Search)

임베딩 기반 검색은 문서의 의미를 기준으로 콘텐츠를 찾도록 해주어, 단순 키워드 매칭을 넘어섭니다. 예컨대 사용자가 입력한 질의가 데이터베이스의 문구와 정확히 일치하지 않아도(동의어, 문장 변형 등) 유사한 의미라면 찾을 수 있습니다. 질의를 벡터로 변환하고, 미리 인덱싱된 벡터들과 비교하여 가장 연관성 높은 결과를 빠르게 찾아냅니다.
6.2 추천 시스템 (Recommendation Systems)
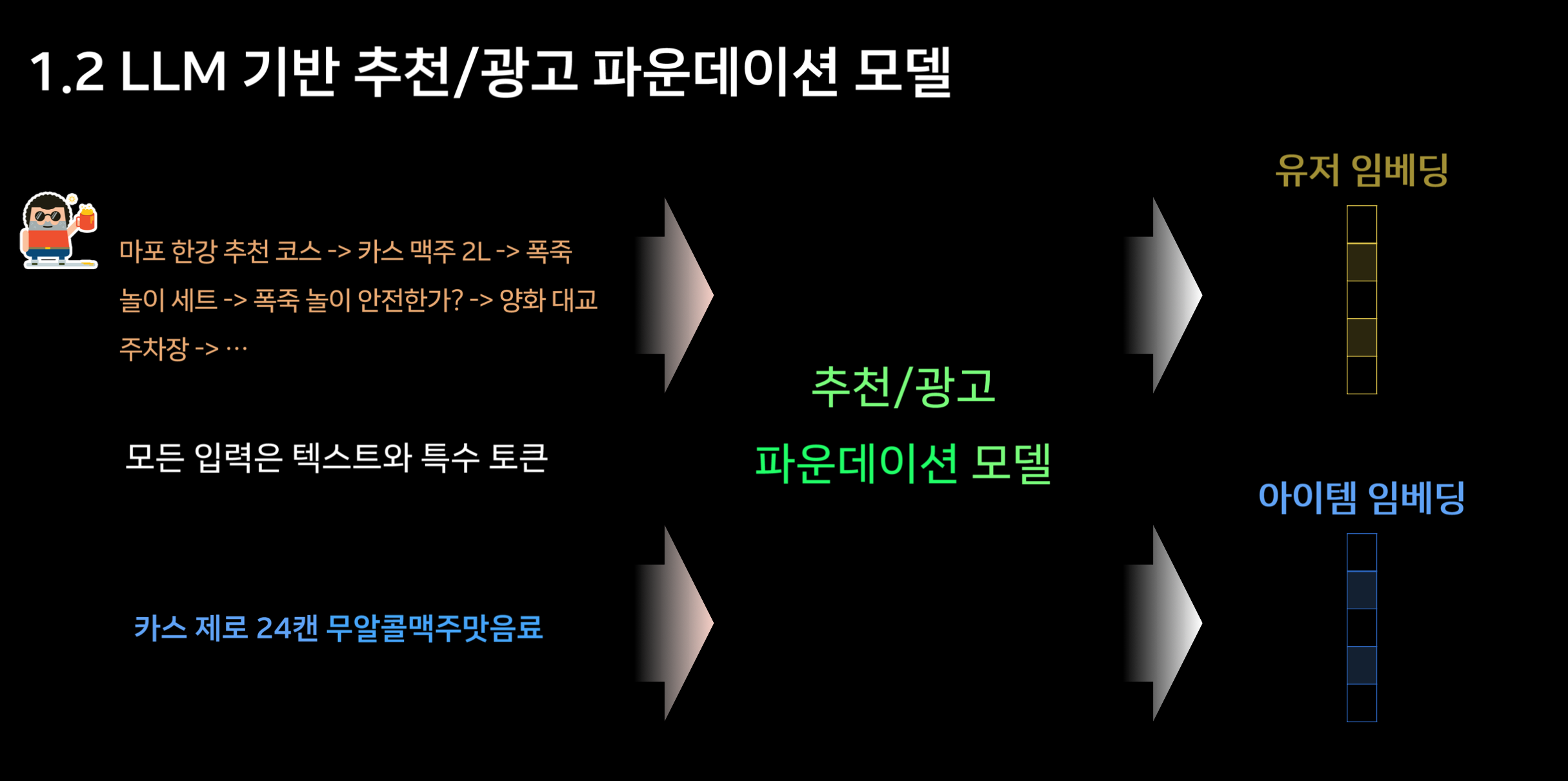
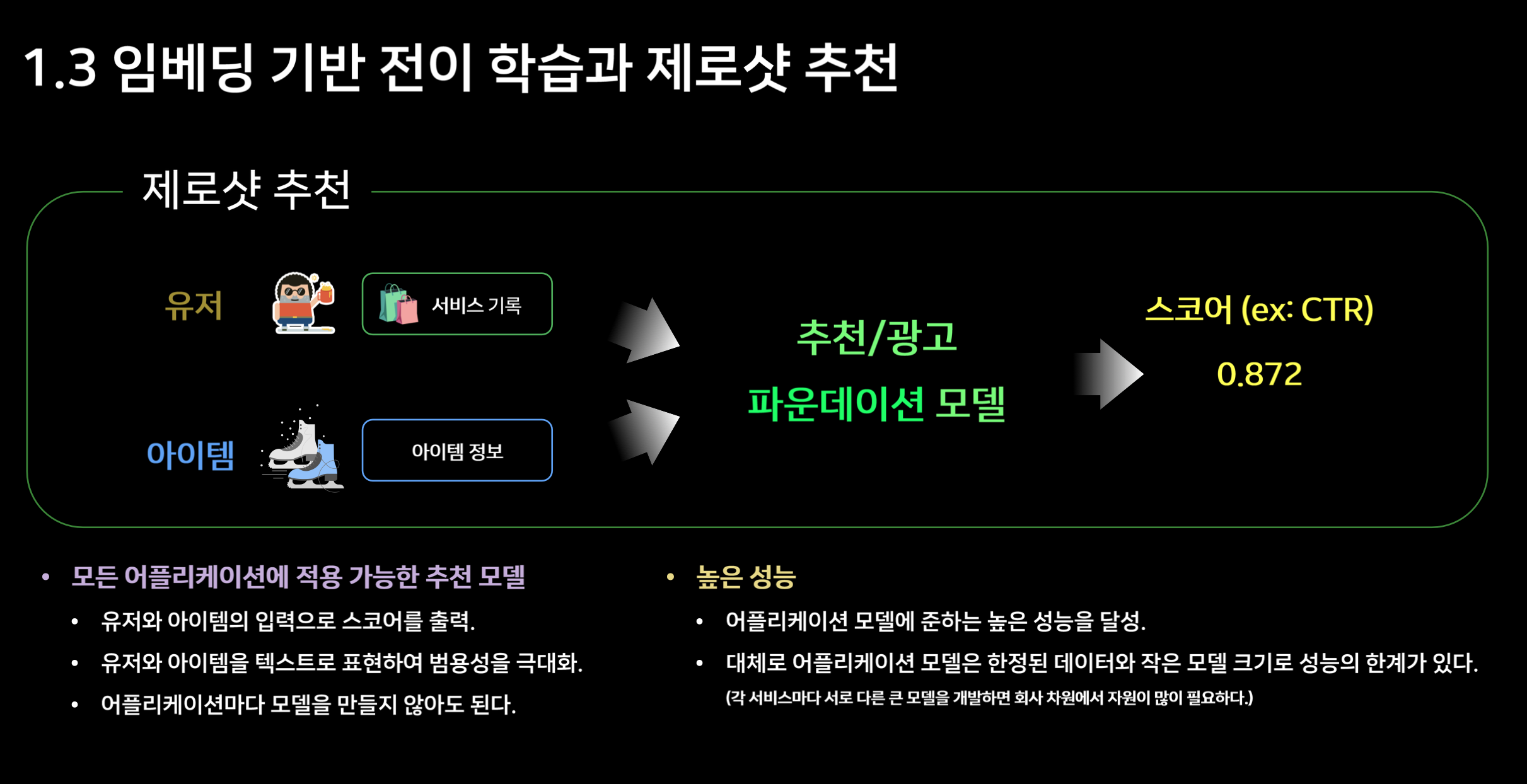
여러 추천 알고리즘은 사용자와 아이템(상품 등)을 임베딩으로 표현해, 동일 벡터 공간에서 가깝게 위치하는 항목을 추천합니다. 이는 과거 협업 필터링을 넘어, 사용자 리뷰나 제품 설명에서 추출한 심층 의미까지 반영할 수 있게 만듭니다. 결과적으로 더 정교한 개인화 추천이 가능합니다.
6.3 질의응답(Question Answering, QA)
밀집 패시지 검색(Dense Passage Retrieval)은 대규모 텍스트 코퍼라에서 관련성 높은 문단을 빠르게 찾는 QA 기법입니다. “프랑스의 수도는?” 같은 질의를 벡터로 만들고, 대규모 말뭉치 내 문단 임베딩들과 비교하여 검색 공간을 대폭 축소합니다. 키워드 기반 방식과 결합하면, 정확도를 더욱 높일 수 있습니다.
6.4 군집화와 토픽 모델링 (Clustering and Topic Modeling)
문서를 동일 임베딩 공간에 투영하면, 비지도 학습으로 비슷한 문서끼리 묶을 수 있습니다. 이는 대규모 텍스트에서 토픽을 발굴하거나, 특정 주제별로 빠르게 그룹화하는 데 유용합니다. t-SNE, UMAP 같은 시각화 기법으로 고차원 벡터를 2D/3D로 표현하면 내재된 주제나 관계를 직관적으로 파악할 수 있습니다.
6.5 멀티모달 활용 사례 (Multimodal Use Cases)
텍스트와 이미지 등 여러 유형의 데이터를 동일 벡터 공간에 맵핑하는 멀티모달 임베딩은 이미지 캡셔닝, 텍스트-이미지 검색, 크로스모달 추천 등 고급 활용을 가능케 합니다. 예컨대 CLIP 같은 모델은 이미지와 텍스트 임베딩을 동일 공간에 배치해, 텍스트 설명으로 이미지를 검색하거나 반대로 이미지를 텍스트로 찾을 수도 있습니다.
7. 결론 (Conclusion)
7.1 핵심 요약 (Key Takeaways)
LLM 임베딩은 시맨틱 검색부터 복합 추천 시스템까지 다양한 애플리케이션에 활력을 불어넣는 강력한 표현 기법입니다. 벡터 데이터베이스는 이러한 임베딩을 대규모로 검색·활용할 수 있도록 하며, 최신 지능형 시스템을 구축하는 데 필수적입니다. 두 기술을 함께 숙지하면 한층 발전된 서비스를 만들 수 있습니다.
Reference:
벡터 검색의 정점에 오르다.pdf
서치피드 - SERP 에서 SURF 로 진화하는 검색_임희재_김세훈.pdf
서치피드 - SERP 에서 SURF 로 진화하는 검색_임희재_김세훈.pdf
네이버페이 결제 서비스 성장과 변화_김진한.pdf
클립 크리에이터와 네이버 유저를 연결하기 숏폼 컨텐츠 개인화 추천.pdf